Humans write documentation
Documenting is instructing or informing someone about the news and evidence related to a specific topic. Therefore, when we write technical documentation, It’s important to understand that we are writing for humans, not machines. We try to help the reader understand the complexity of our system, and to achieve this, we can make use of our extensive and rich language. However, the tools we have for creating documentation don’t always make things easy for us.
For example, in the case of OpenAPI, the most widely used tool for API documentation, we can only add arbitrary text in certain “description” fields. This falls short if we need to elaborate on the explanation of a resource, display examples, images, etc.
Furthermore, JSON and YAML formats are highly oriented towards machine-generated or machine-interpreted purposes, making it very challenging for humans to create and maintain them. Even though there are tools to simplify editing, it’s a format where syntactical definition takes precedence over semantics.
At Devengo, we believe that documentation should be oriented towards people. That’s why we’ve always advocated for using Markdown whenever possible. On the other hand, we also understand the value of syntactical definition when generating schemas, validators, clients, etc. Wouldn’t it be great if we could combine both worlds? As a matter of fact, that tool has existed for years, and it’s called API Blueprint.
Markdown FTW
API Blueprint is a tool that was born in 2013, allowing us to use Markdown as a language to document our APIs. Many people reading this article may have tried it at some point and considered it outdated because it lost the battle against OpenAPI. The latter tool became the industry standard, and all the focus has been on it. However, we believe it is still entirely valid because it provides the principles we mentioned earlier.
The number of artifacts we use in Blueprint is minimal and easy to learn.
Data Structures
It’s the definition of the different data types that the API handles.
If you open that snippet in a Markdown viewer, you won’t have any trouble reading and understanding the data structure. Additionally, it’s straightforward to write.
Endpoints
Once you have defined your data structures, you can use them in the endpoints definition. This is how it looks:
A great thing we can do is define different examples of requests and their responses. This is very convenient for providing examples of erroneous requests with their corresponding error messages. For instance, if we want to simulate a request where the authentication header is missing:
Another typical example would be documenting the case where we omit a required parameter.
The crucial point is that in Markdown, we can define documents in a much more flexible way, alternating between semantic and syntactic documentation as needed. While these files can be easily read with a Markdown reader, there are also tools capable of analysing and understanding the format, allowing us to operationalise the documentation.
доверяй, но проверяй – Testing with Dredd
A widely popularised Russian proverb from the Cold War era says “Trust, but verify” (доверяй, но проверяй , doveryay, no proveryay) – a good practice to apply to our documentation.
As we explained in a previous post, it’s crucial to have living documentation to ensure it remains updated. At Devengo, our main product is an API, so we need the best integration experience and ensure that whatever the documentation states is aligned with the system’s actual behaviour.
One of the tools that allows us to operationalise API Blueprint documentation is Dredd. Personally, I believe this is one of the most useful yet lesser-known tools for API testing. Dredd will run an instance of your web server, automatically read all the requests defined in the document, and send them to this server to validate that the schemas and response codes match what has been documented. How cool is that?
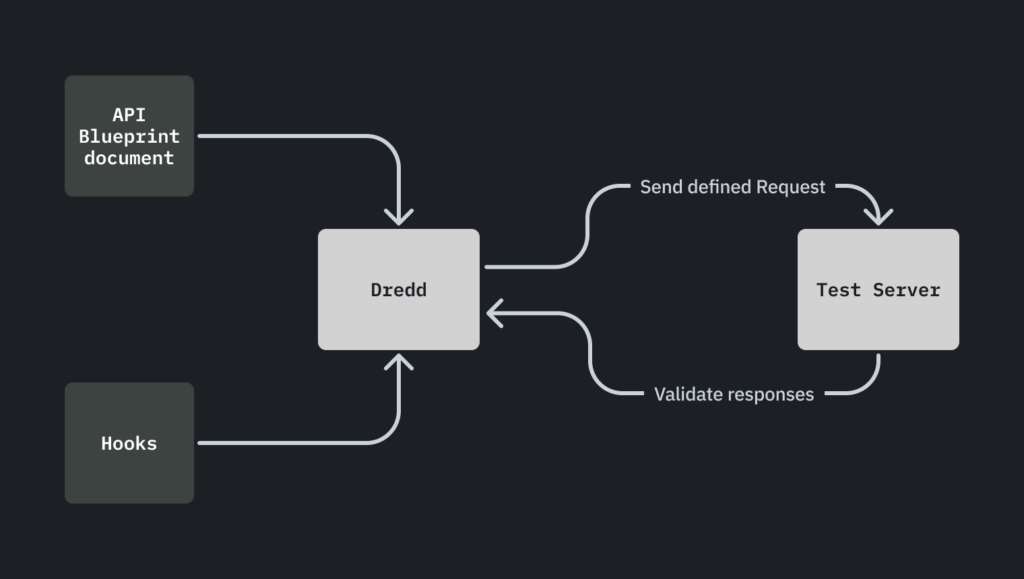
If you liked what you just read but think you won’t be able to use it because you don’t use Blueprint, you should know that Dredd is quite stack-agnostic. It supports both OpenAPI and Blueprint files, and it even has plugins to integrate with various languages.
The installation and configuration of Dredd is very straightforward. You just need to specify the command to start your server, the file where the documentation resides, the endpoint to use, and, optionally, the configuration for hooks.
Providing Clean Data
As you may have inferred, the requests executed by Dredd are real requests against a test server, so they alter the state of resources. You’ll need to be cautious about this, just like in any other end-to-end type of test. For example, you might want to define a couple of different users to test different flows or create a resource only used for testing its deletion on a specific endpoint.
Hooks
Optionally, you can configure hooks that run before or after each request to the server. A good use case is storing the authentication token after the call to the login endpoint and automatically including it in the subsequent requests.
Conclusion
Even if it’s technical, documentation is written by humans and intended for humans. Therefore, it’s crucial for it to be easy to write and read. In this post, we’ve seen how, with just a couple of simple and stack-agnostic tools, we can have a pipeline for generating and testing API documentation. Remember: Doveryay, no Proveryay.